当分析变得毫不费力,每一次聚会都会成为一组数据。
一个朋友从外地来,想庆祝他的生日。
我们决定搞一场盲品糕点比赛,专门比可颂。任何人都可以从自己喜欢的面包店带三个一样的可颂来。最终我们收到了十一份参赛作品,每份切成十二块,每人一块品尝。参与者从第一名(最喜欢)排到第十一名(最不喜欢)。
讨论和争辩都随意,但在所有排名交上来之前,没人知道哪个可颂来自哪家店,也不知道是谁带来的。
一个周六的下午,我们围坐在一张桌子旁,桌上摆满了来自湾区各地的黄油美味,大家仔细咀嚼、高谈阔论、认真记录偏好。
排行榜
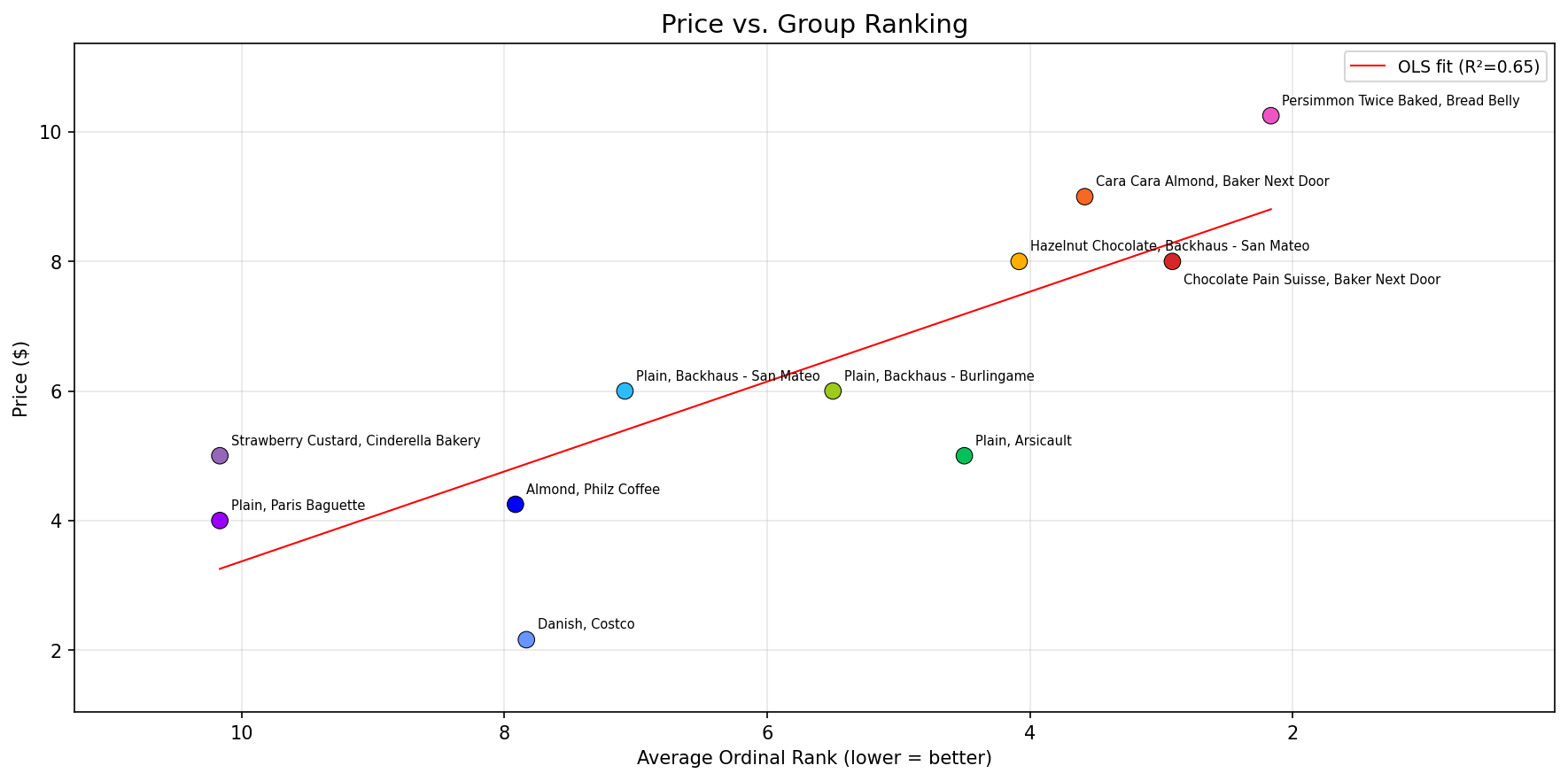
Bread Belly 的柿子二次烘焙可颂以平均排名 2.17 夺冠。没有人把它排到第五名以下。
Baker Next Door 有两款入围前三。Paris Baguette 的原味可颂和 Cinderella Bakery 的草莓卡仕达并列垫底,平均排名 10.17,而这其实是整个数据集中共识最强的一项。大家对于什么难吃的意见,比什么好吃的更统一。
Costco 的丹麦卷,单价 2.16 美元,排在第八。对于一个只有冠军四分之一价格、而且根本不是可颂的东西来说,已经不错了—有些人还因此扣了分。

派对上的笔记本电脑
大家品尝的时候,我打开了笔记本电脑,跑着 Claude Code。在第一口还没咬下去之前,我就给它下了指令:
“准备好用 Python 和 seaborn 为一场糕点品鉴比赛生成表格和可视化图表。”
几分钟之内,框架就搭好了。排名陆续交上来,我把数据录入表格,随时要求即时分析。
“哪个可颂最有争议?”
Backhaus Burlingame 的原味可颂:有人排第二,有人排第十。标准差 2.75,全场最高。
“谁的口味最像?”
Jon Yu、Jack 和 Vincent 形成了一个”口味铁三角”,相关系数超过 0.90—几乎可以互换的味蕾。Kenny 的排名最能代表整个群体的口味。Peter 是经过统计验证的逆行者,与其他所有人的平均相关系数只有 0.553。
“花更多钱真的能买到更好的可颂吗?”
价格-质量回归分析,R-squared 为 0.65,有意义但不算决定性。Arsicault 的原味可颂 5 美元排第五,性价比超出预期。前三名全是 8 美元以上的特色款。
回答这些问题,放在平时都需要把数据加载到 notebook 里,导入 pandas,选择合适的相关分析方法,格式化输出。不算难,但得刻意去做。属于那种你会在派对结束后才做的事—如果你会做的话。
但这一切就在派对进行中发生了。我并没有缩在角落盯着屏幕。感觉更像是发消息—这里问一句,那里输入一段提示词,瞄一眼输出,要求做些小调整。等最后一个可颂排完名的时候,完整的分析不仅已经出来了,而且很精美。
不过,我得坦诚地说,我自己的专业知识确实发挥了作用。我从 seaborn 开始,因为我知道这个库能让 Claude 更容易直接生成好看的图表。我知道对于序数数据,Spearman 相关比 Pearson 更合适。我发现了 CSV 里的重复排名,那些错误本来会悄悄地扭曲结果。我还拿随机基线跑了一遍相关系数来验证数学计算,确保它归零。少了这些检查,输出看起来会一样精美,但会有微妙的错误。
这种知识还能必要多久,我说不准。那天我们用的是笔记本电脑。再过一个月,同样的事情大概用手机就能完成。再往后不久,没人需要知道 Spearman 的存在—模型会自己选择正确的方法,验证输入,自行检查结果,不需要任何人提醒。

毫不费力的深度
那个下午我们产出的东西—相关矩阵、价格回归、争议排名、口味聚类—以前需要更多的意愿。你得有足够的兴趣,在活动结束后坐下来,搭好环境,整理数据,反复迭代。那个努力本身就是一道过滤器。只有你真正想分析的东西,才会被分析。
感觉这道过滤器现在基本没了。每个人都想知道哪个可颂赢了。大部分人对争议之选和价格相关性感兴趣。只有少数人在意完整的相关性热力图。人们真正想要的分析深度是有自然衰减的。
这跟相机的普及有点像。现在每个人口袋里都有一台,围绕它已经形成了一种随意的礼仪:谁想拍食物就拍,大家等一下,没人介意。很快,为了留下记忆,而且意愿的门槛低到它自然而然就成了体验的一部分。也许社交场合的实时数据分析会走同样的路—从新鲜事变成惯例,最终变成大家习以为常的事。
我觉得那天我们没有过头。毕竟是新鲜事,大家玩得很开心。但当借助 AI,每一场晚宴都有人能瞬间挖出隐藏的相关性,为当晚的葡萄酒生成图表的时候呢?我不确定分析还能继续像派对魔术那样令人兴奋。
十年的重新校准
2016 年,我在研究 LSTM 的时候,模型能正确处理英语复数就已经让人真心兴奋了。该加 s 的时候加,该省略的时候省略。这在当时是可以发论文的进步,真的发了。
十年后,我在一个生日派对上让 AI 实时回答关于群体可颂偏好相关性的问题,大家的反应是”哦,挺酷的。”不是震惊。只是……挺酷的。
我一直在想这两个时刻之间的距离。我们重新校准的速度有多快。每一种新能力几乎在出现的瞬间就被吸收进了基准线。有时候感觉,一件事让人觉得了不起的时间窗口,正在以比能力增长更快的速度缩小。
确实需要真正有意识地停下来,意识到我们正身处人类技术史上最快的能力跃迁之一,而我们中的大多数人—包括我自己—已经对此有点麻木了。
这一切值什么?
那么,所有那些分析的价值究竟在哪里?
它让朋友的生日更好玩了。它给了我们在”这个好吃、那个难吃”之外更多可以聊和争论的话题。Peter 将永远是经过认证的逆行者。我们发现 Costco 的丹麦卷和 Arsicault 的原味可颂是当之无愧的性价比之选。我们留下了漂亮的记录,以后可以发给彼此,再笑一回。
也许这就够了。也许价值并不真的在于那些洞察,而在于它为我们本来就在一起做的事增添的质感。又或者,我只是在合理化一个拿着 Claude Code 的数据爱好者拿到新鲜数据后一通猛干的结果。
苏格拉底说,未经审视的人生不值得过,但被过度审视的人生,是否更值得一过?
不管怎样,Bread Belly 赢了,而且赢得并不那么接近。
完整的分析、代码和数据都在 GitHub 上,这不是理所当然的嘛。
