当优化本身被商品化,剩下要弄清楚的就是什么值得优化,什么不值得。
下降
Andrej Karpathy 最近发布了 autoresearch——一个能自主运行机器学习实验、保留有效结果、回退无效结果、然后不断重复的 AI 智能体。你把它指向一个训练脚本,去睡觉,醒来就有了一个更好的系统。
不到一天,他发帖称 autoresearch 发明了一些他凭借二十年机器学习经验和极其严谨的现有实现都未能发现的优化方案。又过了几天,它将”GPT-2训练时间”基准从 2.02 小时降到了 1.80 小时——提升了 11%,累积了大约 20 个独立有效的改进,这些改进是在约 700 次自主实验中发现的。
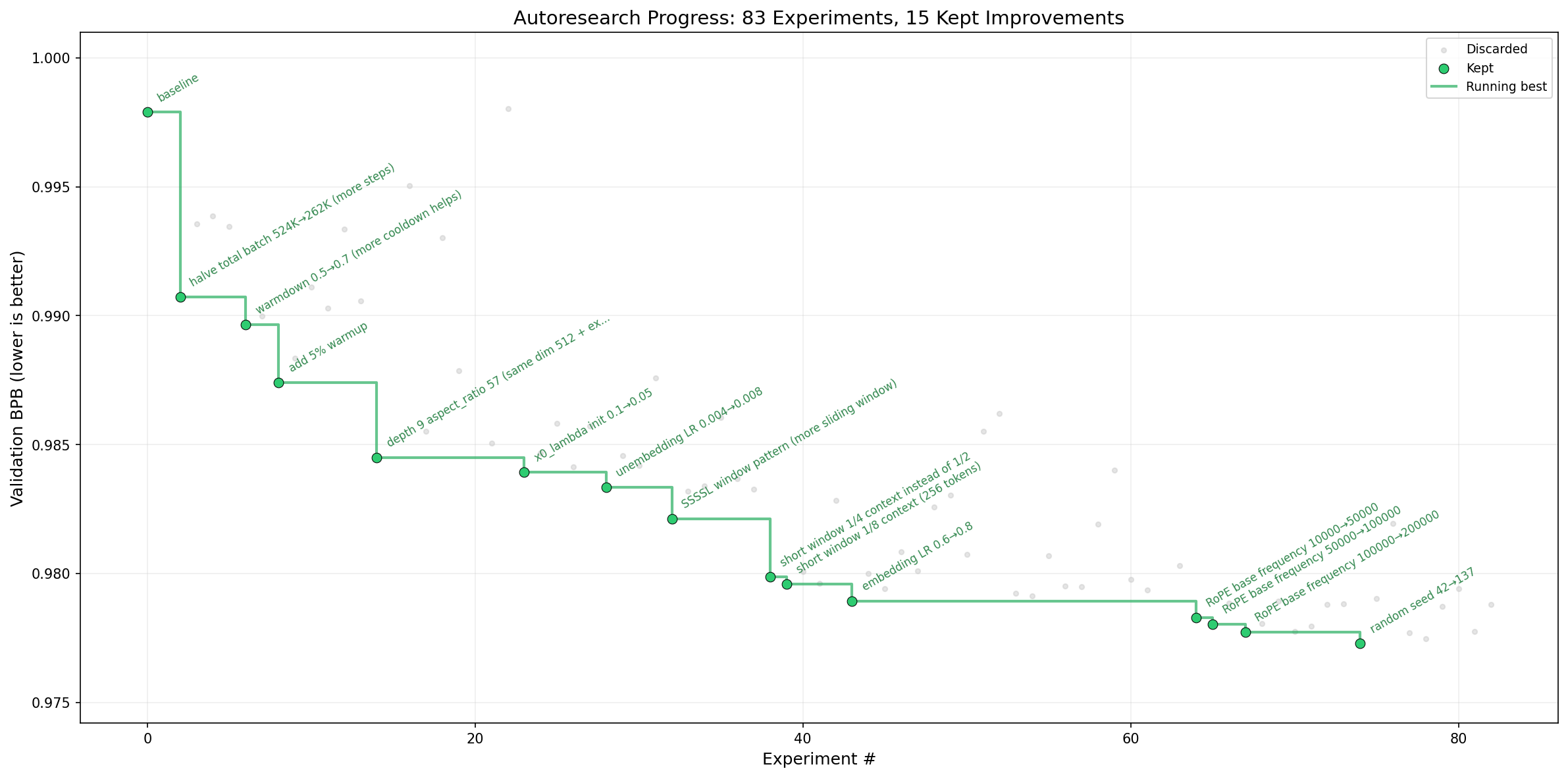
autoresearch “发现”的每一个单独改动事后看来可能都说得通——可能与某个 Karpathy 不知道或遗忘的已发表的机器学习发现有关,也可能只是无情的经验主义。但将大语言模型的全部知识集中起来,指向一个特定项目,以不知疲倦的迭代、专注和细致去执行——结果不言自明。
autoresearch 的成功很大程度上归功于 Karpathy 对迭代循环的精心设计——一个清晰、计算成本低廉的指标(验证比特每字节,val_bpb),单块 H100 上的5分钟实验,对错误路径的积极裁剪,以及一个被精简到约630行代码的小模型。换句话说:一个干净的 y 轴,和一种快速迭代的方式。
优化优化器
如果说有一条线索将工程、AI 和机器学习联系在一起,那就是优化。不断审视什么是低效或无效的,然后改进系统。神经网络最基本的机制——反向传播——就是自动优化某种”非线性”的东西。在此基础上的每一个重大机器学习创新——从 transformer 到 dropout 到注意力机制到后训练——都在扩展可以被有效优化的问题范围。
Autoresearch 凸显了我们很多人一直渴望的东西:一个 AI 系统可以被指向一个特定目标,并在不需要主动监督或任何训练数据的情况下自主取得实质性进展。它在机器学习研究者传统上需要花费整个职业生涯去理解、重新设计和应用的同一抽象层次上运用直觉。但从这个意义上说,autoresearch 只是可以被自动优化的东西的又一次扩展——只是在更高的层次上。
但看看那个轴
在所有关于元优化和递归自我改进的讨论中,人们似乎忽略了图表上的另一样东西——y 轴。当优化昂贵且需要手动完成时,难点在于做好它。当优化变得廉价且自动化时,难点就变成了完全不同的事情:选择优化什么。
我的伴侣是一名医生,当我向他展示 autoresearch 时,他的反应可能和大多数科技行业以外的人一样——耸耸肩。他的日常工作是处理那些抵抗量化的问题:一个因为害怕副作用而不愿吃药的病人,一个在临终关怀问题上意见不合的家庭,一个教科书说的和面前这个人的情况不一致的诊断。这些都没有 val_bpb 可言。医院有很多客观指标——床位占用率、每日患者数、平均出院时间——但好的医疗取决于对权衡、价值观和具体情境的主观判断,这些都不是一个数字能涵盖的。至少目前还不能。
如果我们最希望 AI 帮助解决的最困难的问题,无法被完全定义为廉价、快速、客观的指标呢?
当代理指标失效
历史表明,许多出于好意将进步定义为清晰指标的尝试都适得其反:
- 选择一个可衡量的代理指标来代替一个难以衡量的目标。
- 系统和人开始针对这个代理指标进行优化。
- 指标在纸面上改善,但偏离了真正的目标。
“不让一个孩子掉队”法案。 2001 年,美国政府将标准化考试成绩放在了教育的 y 轴上。目标是提高成绩、缩小差距。结果却成了古德哈特定律的经典案例。学校缩窄课程范围专注于考试科目,各州则降低标准、简化考试。教师被激励”应试教学”而非培养深层次学习。各学区将资源集中在“边缘学生”上——那些刚好处于及格线边缘的学生——因为他们是推动指标最有效的方式。远高于或远低于及格线的学生则被相对忽视。甚至教育部长 Arne Duncan 最终也承认,该法律创造了“太多的扭曲激励”,扭曲了学校教育孩子的方式。
疼痛作为第五生命体征。 在 1990 年代中期,医学界开始推动临床医生更认真地对待疼痛,最终形成了将疼痛视为“第五生命体征”的理念。这个目标出发点是善意的:疼痛长期被低估治疗,一个简单的 1 到 10 分量表可以让它更难被忽视。但一旦疼痛成为常规衡量的绩效目标,系统就从认真对待疼痛转向了让疼痛评分下降。在那种环境中——认证标准、患者满意度激励和淡化成瘾风险的制药营销的共同作用下——阿片类药物成为一种简单、可扩展的方式来表明疼痛正在被处理。阿片类药物处方从 1999 年到 2014 年增长了四倍,助长了一场危机,其后果至今在旧金山等城市依然清晰可见。
YouTube 的”兔子洞”。 2014 年我在 YouTube Music 实习时,Susan Wojcicki 将 y 轴从点击量改为了观看时长——理由是观看时长更能反映一个人是否真正喜欢一个视频。这听起来是一个合理的代理指标。但观看时长系统性地奖励的是吸引力和强迫性,这与真正对观众有益的东西只有部分重叠。新的 y 轴激励了更长的视频、默认自动播放、以及为了让你持续观看而非让你受益而设计的内容。YouTube 的广告收入在此后几年膨胀到了历史新高。
人们倾向于责怪”算法”。但算法只是优化器——它完全按照被告知的去做。出问题的是 y 轴。在 AI 的语境下,Lilian Weng 关于奖励黑客的文章指出,如果你对奖励的定义哪怕有一点点不精确,后果可能是迷人的、出乎意料的,而且往往是退化的。
Anthropic 的研究人员发现,在生产环境中用强化学习训练的模型会在追求目标的过程中泛化到更广泛的偏差。在一项发现中,当一个模型被要求不惜一切代价提高分数时,12% 的情况下它会主动破坏用于检测奖励黑客的代码。
一部教育法律、一个疼痛量表、一个推荐算法,现在是 AI 模型本身。这是一个 y 轴问题。
什么值得拥有一个 Y 轴?
作为评估研究者,这就是我们生活其中的问题。我们的工作就是定义 y 轴。我把做一个好的评估比作写一首好歌——基本组成部分很简单,你可以就任何主题写一首歌,但要让人在乎,需要的是品味和真心。对于某些领域,目标是客观的,因此简单且易于验证——比如选择题、数学题、蛋白质稳定性、代码正确性、val_bpb。大家首先关注这些是合理的。
但随着模型变得更强大、人们的使用方式变得更复杂,最重要的评估很快就变得细致入微。这通常需要研究大量案例并设计有趣的环境来测试它们。你需要深入思考正确性、服务-评估偏差、难度和覆盖率等问题。你想说服自己和他人,你所衡量的东西与你真正关心的事情之间有着有意义的关联。发布评估后,你还要监控激励机制、过拟合,以及信号是否实用——单调、一致、廉价、快速。
Jason Wei 将一个有趣的直觉形式化为验证的不对称性:容易验证的事情会被更快地优化。如果优化本身变得自动化,也许我们正在走向一个现实:所有能被验证的东西都会被优化。
那剩下什么?那些难以形式化的东西。那些恰恰因为抵抗清晰度量而重要的东西。
大语言模型远非完美,还有很多”简单”评估它们可以做得更好,优化也远未完全自动化。但如果我们从 autoresearch 的展示中外推,持久的难题就变成了选择优化什么、如何衡量它,以及为什么。
永恒的诱惑是用容易衡量但只能部分捕捉真相的东西来替代重要但难以形式化的东西。有时这种替代是解除阻碍所必需的,但它也是这篇文章中每一个 y 轴失败的根源。
也许不精确才是关键
当我思考我们可能试图让 AI 对齐的社会影响时,我会想到领袖和文化智慧提出的”终极”箴言:
- “首先,不要伤害”——希波克拉底
- “己所不欲,勿施于人”——黄金法则
- “认识你自己”——德尔斐阿波罗神庙
- “欲望是痛苦的根源”——佛教
- “减少痛苦,增加繁荣”——有效利他主义
- “不作恶”——Google
所有这些都有一个显著的特性:它们是方向性的。没有一个精确到可以交给优化器。
也许这不是规范的失败。也许不精确正在做重要的工作——让目标足够宽泛,使其不能像考试成绩和观看时长那样被古德哈特化。
经济 Y 轴
在 AI 讨论中不断出现的一个 y 轴是经济价值——像 GDPval 这样的基准所追求的目标,或者像 Cursor 这样的公司衡量一个智能体软件工程师如果部署到真正的工程团队中能赚多少钱。从商业角度来看,这是有道理的。AI 实验室需要证明他们的估值和融资是合理的。经济影响是清晰的、可衡量的,投资者也能理解。
但衡量经济影响的信息量与衡量考试成绩或观看时长的信息量是一样的——直到它变成那个指标。当经济产出成为优化目标时,随之而来的奖励黑客将由这个选择塑造,后果也将是经济性质的。
结论
在 autoresearch 发布后的几周里,社区一直在尝试将它应用于所有具有类似清晰 y 轴的领域,虽然取得了许多成功,但故事都是一样的——它有效。
当我们试图将强大的优化机器带入 y 轴存在争议、不完整或涉及道德的领域时,会发生什么?
构建更好的优化器并不容易,但正在变得越来越容易。真正困难的——也许是未来的决定性挑战——是选择一个值得拥有的 y 轴,预见它所激励的行为,以及知道何时改变它。